cprats
-
Posts
143 -
Joined
-
Last visited
-
Days Won
5
Recent Profile Visitors
4,135 profile views


cprats's Achievements
")
Newbie (1/14)
30
Reputation
-
In my opinion, we cannot let die the best ecommerce software I've ever seen, and we must do whatever is necessary to guarantee this goes on. We could all migrate to PS1.7, but I don't want to rely on that software: headaches suddenly ended when I met TB. I am a PS1.6 refugee from the time it was announced support would be stopped to favour 1.7, and I won't go back.
-
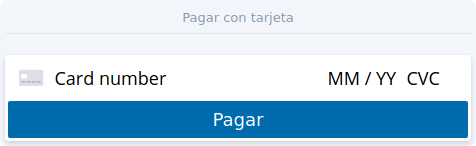
I need to translate Stirpe, but I could do that only partially: In Translations - Installed modules I could only translate "Pay with card" (Pagar con tarjeta) and "Pay now" button (Pagar). The fields "card number, "MMYY" and "CVV" do not appear there. How can I complete the translation?

-
Possibly it is not worth it: it labels as "vulnerabilities" libraries [email protected] and [email protected], but most probably Google relies on this tool for SEO.
-
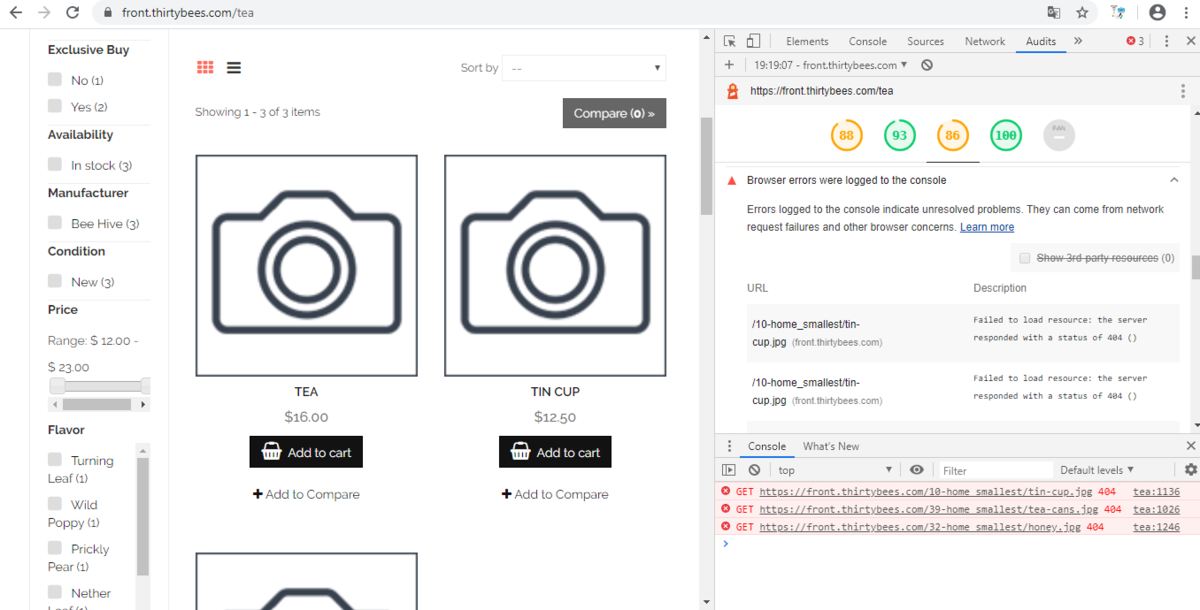
Hello, Testing with Google Audits (Lighthouse) I've noticed that the category images, perfectly showing when Crhome charges the page, do not show after an audit is performed, and they show up again when you close the right window of the audit. Here what I say (and I take as example the thirtybees demo site https://front.thirtybees.com/ ). Mine has the same problem, while others don't. Under "best practices" section, messages warn this: Failed to load resource: the server responded with a status of 404 () Does anyone have any idea of why this happens?
-
I did a little hack with @datakick Blackhole for Bad Bots wonderful module and .htaccess again. Here is what I did to alternatively solve this issue without having to block large ranges of IPs: I've changed the contact-us friendly url to domain.com/random-url I've set disallow rules for bots under robots txt for the former url /*contact-us. Nothing better to get sure spambots will use that link than setting a disallow rule for it. I've redirected domain.com/contact-us to blackhole for bad bots in .htaccess file and I've had some fun watching that pest being trapped there. Here's the .htaccess code for if anyone needs it: Redirect 302 /contact-us https://www.yourdomain.com/modules/blackholebots/blackhole/ (remember to change the /contact-us url for your contact page to anything else and to clear cache before making the redirect in .htaccess)
-
One of my sites has recently been flooded with spam mail through contact form, with some 10,000 emails from qq dot com addresses. As the system sends a confirmation message to the sender ("Your message has been correctly sent"), I had the same amount of outgoing mail, and the hosting company suspended outgoing mail from the domain. I installed the No Captcha reCAPTCHA module, and I also blocked all Chinese IP ranges through .htaccess, and this stopped the flood of junk mail. As this website is based in the US I could use the Captcha module with no worries about cookies and EU laws, but here is the question: what happens if one of my sites based in the EU is spam bombarded? Using cookies there would be quite more complicated, as I would need to block all cookies with a GPRD module, and wait and see if the visitor wanted to allow cookies on his computer of if he ever bothered to click the "accept" button on a bottom bar. Meanwhile, as cookies should be disabled for Captcha until visitor's acceptance, Chinese bots would be able to continue spamming with no limits, as Captcha would not display for them neither unless they accidentally clicked on the "accept cookies" button. Is there a way to avoid sending the "Your message has been correctly sent" message when contact form is used?
-
You could also use "Bankwire Module" and instead of giving a bank account number through it, you could write down instructions on other offline payment methods, or offer them alongside with a bank account number if you need this module to enable bank wires.
-
Blackhole for Bad Bots is a free module by @datakick very useful to block disrespectful crawlers. The system is very simple and effective: the module traps and blocks any originating IP for any bot crawling the directory /blackhole/, that has a disallow rule for all agents in robots.txt file. But using .htaccess this module can also be very helpful to block a very large sort of nefandous hits by spammers, scanners, scammers, etc, etc, etc. I recently had an issue with spammer bots generating fake shopping carts, and Blackhole for Bad Bots module helped to stop that flood of garbage. All bots entered the site hitting a non existent folder, and they all followed this pattern. The result, after some code in .htaccess to redirect such visits to the black hole, was the complete annihilation of such annoyance. Here is another example of what Blackhole for Bad Bots module can do for you, beyond of trapping nasty crawlers: for sure you get dozens of hits to non existent wp-login.php file, or to xmlrpc.php. You should host your thirtybees installation alone in a server and not to mix it with other websites running WordPress (this is why you should do this). Here is a way to have fun with WordPress' brute force bots hitting thirtybees. Place this code in your .htaccess file: Redirect 302 /wp-login.php https://www.your-domain-name.com/modules/blackholebots/blackhole/ Redirect 302 /wp-config.php https://www.your-domain-name.com/modules/blackholebots/blackhole/ Redirect 302 /xmlrpc.php https://www.your-domain-name.com/modules/blackholebots/blackhole/ I've just redirected the hits that return a page-not-found.html that spends 33887 bytes. After the redirection to the black hole, the size of the file served is just 243 bytes, as the bot gets the module's ban warning, which is text only. So this will save you bandwidth and it will also block the source IP for that attack. See in your server logs what your needs are, and modify the redirections at your convenience. Of course, needless to say, never redirect to the black hole a folder or a file that effectively is in your server. If you have to block it, it is better to delete it. Redirect only bind hits to non existent files/folders by probe bots that only make you waste bandwidth.
-
Here it is how I've managed this issue, for if it happens it can be useful to anyone else. I did this through htaccess and apparently it works: Redirect 302 /en/11111111111111111112222ct11111111111111111112222/ https://www.xxx.com/modules/blackholebots/blackhole/
-
This is exactly what bots do: 185.32.222.115 - - [04/Feb/2020:01:52:55 -0500] "GET /en/11111111111111111112222ct11111111111111111112222/ HTTP/1.0" 404 33888 "https://www.xxx.com/en/11111111111111111112222ct11111111111111111112222/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:52:55 -0500] "GET / HTTP/1.0" 301 - "https://xxx.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:52:56 -0500] "GET / HTTP/1.0" 301 - "https://www.xxx.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:52:57 -0500] "GET /en/ HTTP/1.0" 200 34870 "https://www.xxx.com/en/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:52:58 -0500] "GET /en/post-war HTTP/1.0" 200 241360 "https://www.xxx.com/en/post-war" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:53:01 -0500] "GET /en/cart?add=1&id_product=19428&token=9fg8673114e862a47705t5c92gcr42d8 HTTP/1.0" 302 - "https://www.xxx.com/en/cart?add=1&id_product=19428&token=6df7174591c401b74915h1d53rvt78y9" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:53:01 -0500] "GET /en/order?ipa=19428 HTTP/1.0" 302 - "https://www.xxx.com/en/order?ipa=19428" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:53:02 -0500] "GET /en/quick-order HTTP/1.0" 200 233983 "https://www.xxx.com/en/quick-order" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36" 185.32.222.115 - - [04/Feb/2020:01:53:05 -0500] "POST /en/authentication HTTP/1.0" 200 153154 "https://www.xxx.com/en/quick-order" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36"
-
I have several tens of hits a day to a non existent folder: /en/11111111111111111112222ct11111111111111111112222/ This results in the creation of fake shopping carts, as the intention of the bot is to post spam in a non existent forum or to send spam email through a product page instead of from the contact form. Can Bad Bots Blackhole be used to block the originating IPs of such annoyance? Instead, any htaccess code to redirect bots hitting such a directory anywhere else, preferably a black hole or poisonous website? Thank-you.
-
-
Thank-you. I stopped the attack while it was ongoig by blocking the IP yesterday afternoon, and since then it has not started again from anywhere else.
-
Thanks for the reply. Should I worry for what happened? How can I check if this has had consequences?