


Mark
-
Posts
276 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Gallery
Downloads
Articles
Store
Blogs
Posts posted by Mark
-
-
On 10/23/2021 at 2:18 AM, datakick said:
@musicmaster / @Mark thanks for the questions. I don't have time to answer right now, but I'll make sure to reserver some time for detailed explanation of both features later, sometimes during the weekend.
Apppreciate it @datakick
-
On 10/23/2021 at 2:18 AM, datakick said:
@musicmaster / @Mark thanks for the questions. I don't have time to answer right now, but I'll make sure to reserver some time for detailed explanation of both features later, sometimes during the weekend.
Look forward to it @datakick
-
What exactly is tb tracking? Is it just errors, where is the data that's being sent to the API?
Or is it non error tracking as well?
What exact data are you tracking please, where is data stored that we send and how is that going to help a) tb b) the merchant
I thought there was going to be a permission system on what data would be sent to tb @datakick?
-
I got this ajax error when updating database ....
There were hundreds of files that needed updating.... A bit daunting to do that... Maybe a "don't worry" about it comment?
-
Something that tracks a referrer code on any page like this soon-to-be-doomed core feature claims to and where someone can login and see what the clicks and resulting sales and user actions were (of those clicks) without logging into admin.
Tracking clicks to sales might not be straightforward and neither might a login page.
This core feature does have that stuff but it's pretty complex like Datakick says... And pretty sketchy at best.
-
22 minutes ago, wakabayashi said:
@Mark The answer is almost the same in my case. It's: genzo_affiliate. Which means it's my own development.
While most of my mobiles are out of question, to be maked public. I could consider to release this one day. It's very small without a lot of features. But on the other it's very clean IMO. BTW it's really only affiliate and not referal.
Btw: How do you know I am using affiliate? Did you check my sites source code?
No lol I don't even know what your site is. You mentioned about affiliates being one of being the only modules you really use outside core a few days ago. So I thought I'd see what module you used. Looks like Datakick is going to seriously consider dropping this from Core (understandably) and Im after an Affiliate module
-
1 hour ago, datakick said:
It works properly, or at least it works as it was designed.
There are couple of gotchas.
- make sure you 'Save direct traffic' enabled, otherwise your testing will not work. When you test by entering url into browser, it's considered direct traffic -- there's no referral http header.
- When you define request uri include key, you need to surround it with '%', as it is basically a sql subexpression. For example, if you want to attribute links with &referrer=123, you should use '%referrer=123%'. You can't simply write 'referrer=123', because it would not match -- the resulting sql looks something like this 'AND url LIKE "referrer=123"'
- Every time you change the referrer, you should rebuild the index.
- And you need to refresh the cache regularly, or the list will not display up to date informations.
I must say, this is one of the most f*cked up feature in the core. It's way too complicated, depends on caches and other transient data, it's hard to set up and debug,... and nobody is using it. This it the prime candidate for removal, or at least to transfer to
I definitely enjoyed that response cheers @datakick 🙂. The bit I was initially referring to is a login portal where Affiliates go to see their clicks and referrals and so on, it doesnt work at all. As far as recording the data, Ive tried what you suggest but I couldn't get it going particularly easily.
I agree this should not be Core, it should be a module that people can pay for and it should be much better, more bullet proof and reliable than this. I see you use Affiliate tracking @wakabayashi how do you do it?, Which module?
-
 On 7/1/2021 at 2:53 PM, Mark said:
On 7/1/2021 at 2:53 PM, Mark said:@datakick when will modules/trackingfront/stats.php be fixed and this affiliate tracking finally fixed?
Been waiting about 1.25 years for this to be fixed @datakick. Has it been fixed in the 1.3 upgrade at all? Looks like the Stats module is the problem?
Referral agents also appear to not be working.... if I create jjj as a Request_URI key ... then access url?jjj then nothing gets recorded
-
23 hours ago, wakabayashi said:
Btw: I worked like 10 hours at the weekend to push my theme project a bit forward. I am very happy with the progress. 😎
IMO I already found a very stupid behaviour that each theme copies from the other themes (root is probably 1.6 PS theme), but was probably never intended to do so. If you have ever looked into the tpl files, you have maybe noticed that some tags are opened in header.tpl and closed in footer.tpl. Very unnecessary... Just use layout.tpl for it. Such stuff is the reason, why I prefer to do it from an empty folder.
Hopefully you'll see a way to take this that might not be as bad as it first looks (or at least you'll be able to define exactly whats involved) and maybe others will help you in that if you provide the framework by which to do it.
-
On 9/24/2021 at 8:51 PM, haylau said:
Or
Rather than re-inventing the wheel, could the 'owners' of thirtybees have conversations with some of those theme developers (only the best / most configurable themes) and offer a one off payment to adopt that theme as the new default theme and simply port it across and adopt it as the standard theme when TB is installed making it effectively open source. Perhaps the theme (Panda? @Jonny?) could actually supply a slightly cut down version with big advertising within their theme for the extra modules so they gain even more?
I am sure some of us would financially support that one off payment - I am sure it would not be too much as they won't really be getting many sales from ThirtyBees customers anyway.
Many of these themes are highly configurable and work with templates which can be imported and exported, then:
@jollyfrog could dessign some standard templates with help from users such as @Mark and @led24ee and @cienislaw who have perhaps some specific design features in mind
And them some development of the theme would be down to devs like @datakick, as part of the thirtybees environment, but other great devs like @wakabayashi, @yaniv14 are more likely to submit improvements and bug fixes on Github?
Win/Win??
I asked this earlier in this topic of @Smile and got no response unfortunately @haylau
I have spoken to the Panda makers once who said they'd like to help but
a) its a big piece of work
b) TB base is too small
Doing this kind of work is, in all fairness, beyond the realm of volunteer work and its not surprising the guys here reluctant to help out.
What I could see working possibly is this:
The theme could be built as a collaboration between Panda (for example) and the guys here. We do very much need this. What we have is all we have, and it isnt enough now, let alone the future.
Panda have done this before, they will probably know the best path under collaboration from people here.
Smile needs to talk to Panda, he's the boss, its his baby.
BOTTOM LINE:
We members are going to have to pay for it, and we should have expectations around what we get. The money we pay should go to thirtybees, and Smile the owner of thirtybees, should pay Panda to get the work done with help from the guys here to keep costs down.
Without this, thirtybees gets closer to to its own untimely demise.
-
3 hours ago, datakick said:
I don't think there is any such mechanism in the core. You might have some module installed (blackhole for bots, for example). Maybe some security apache module. Or the crawler could be flagged by couldflare or similar proxy you might be using
Following a rather disconcerting hack even through Cloudflare I do use Cloudflare to block just about every country I dont intend trading in to some degree now (except search engines). I also use your blackhole for bots, however they arent crawling, just accessing image url's I give them, so its probably not that. Right?
I did whitelist their ip, but its probably Cloudflare, I'll raise it in that community
Thanks.
-
I'm wanting specific third party sites to upload my images for product listing purposes however they can't and neither can https://imgdownloader.com/
Is there some mechanism TB has which prevents this other sites from doing this?
If so ... can it be overruled for specific IP's.?
-
Leaving out most 3rd party modules is a totally understandable thing from a build point of view. I agree minimal is good, however it's obviously a pretty terminal thing for those modules people have or want if they aren't compatible so there needs be a clear process for assessing and handling what modules will no longer work properly/at all with the theme and what options the site owner has ... and what module developers need to do to get the module compatible.
-
Awesome @yaniv14 are we going to get requirements for this and know what users want, then start to work out what is involved and whos going to do what? We should have a list of all users, then wants.... Then work out the doable list from that.
-
Certainly sounds like a pretty dire need to get a quality theme going.... But from scratch @wakabayashi?? That sounds like an incredibly long hard road? Wouldnt it be easier to take an existing great theme like say Panda (that doesnt work properly with TB unfortunately), and speak to Sunnytoo (the maker of Panda). I spoke to him once before and it was just too much work for small sales to get it compatible with TB.
Maybe if the talents here that have already volunteered to help could make Sunnytoo's life easier getting it compatible then it we could have something high class for TB?
His code is obviously not open source (a far as I know).
I am sure many here including me would pay for a decent theme (or at least components of a decent theme), it is a pretty large achilles heel with TB.
-
I'd love to see sunnytoo get back involved. He makes Panda etc but looks like he gave up on TB? Can he be spoken with to help out @Smile
with the theme.. its pretty important that front end is just as good as back end -
It would interesting to hear where you guys are at with doing this theme. Are you still interested or not so much anymore?
-
Does anyone have a good understanding of what themes are currently compatible and will be compatible with the next upgrade of TB?
I use Niara, Im of the belief that its about the only thing thats compatible with TB and modernish - given that sunnytoo has moved on from TB.
I dont particularly like Niara, its pretty dated especially the checkout page. But I dont believe there's anything better, can someone prove me wrong?
-
My site says its upgraded to 1.3 .... dont ask me how that happened though as I purposefully didnt do it knowing it could be hazardous... however it works fine fortunately
-
49 minutes ago, datakick said:
You can download my Consequences module and use it to block the outgoing email. I'm using it myself.
Brilliant thanks had totally forgotten about this module since the rebuild also. Thanks @datakick
-
56 minutes ago, datakick said:
This is not usually what happens. Spammers use email addresses of real people, not their own. They are abusing your server to act as a sender of spam mails. Of course, they occasionally use their own email address to check that the emails are sent, but in most cases they use real email addresses.
The most efficient way to mitigate this is to block outgoing contact_form emails. Spammers will have no reason to abuse your website, if it does not send emails to end users
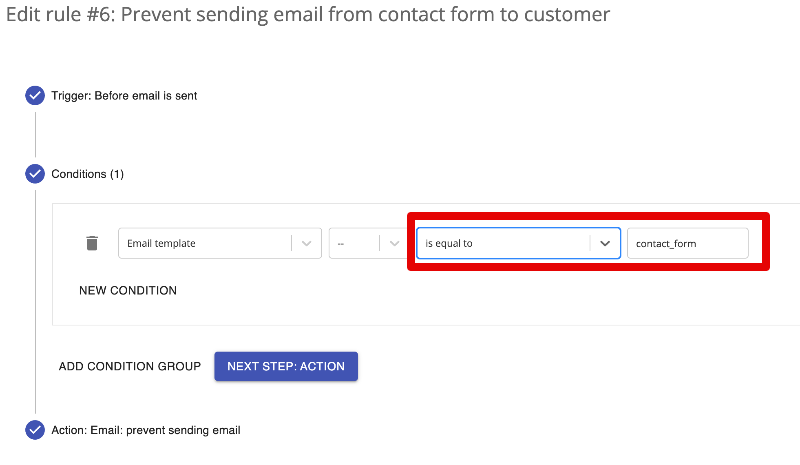
You are bound to be right @datakick, but in my sendinblue account, a number of spam accounts have hard bounced... I dont know why...I just know Ive been ratelimited as a result... Is there a UI way to block contact_form emails? or will I need to make code adjustments...?
By the way thanks @AndyC I did have that running before my old site was hacked, I hadnt resurrected it on the rebuilt site so thanks for the reminder. -
What are people using to control spam?
There's two problems
1/ The incoming spam itself
2/ The mail that is sent to spammers confirming their message has been processed.
In the second case, sending the spammers an email confirmation, usually to fake emails, causes hard bounces and therefore degrades credibility with 3rd party mail providers (I use sendinblue). This loss of credibility means real users mail arrives more slowly.
-
Shouldn't updates be switched off and unavailable until the module is ready?
From what @datakick
was saying it could be hazardous to upgrade without the module mods -
I have version 1.2 ... I went to Core Updater and noticed many files ready to update presumably for 1.3. By good fortune I read this first. However I went to Modules and checked for updates, particularly for Core Updater module but it said Core Updater was up to date, which seemed odd given your comments above @datakick
I'm not sure now whether to just go ahead with Core Updater, given that the module hasn't been updated... I don't want to stuff the db trying to update
Newsletter update Oktober 2021! Version 1.3.0 is here & new backer perks!
in Announcements about thirty bees
Posted · Edited by Mark
Great answer thanks @datakick and all important groundwork for the future of TB. Sounds like, for non anonymised and specific data, there will be a consent process put in place, which is where I was coming from. I did mention and suggest that TB did this myself probably a year or so ago, so its good to see it begin to happen... ! It would be great for us to see exactly what data was actually sent to TB at some point.